

Introducing KAT-Dev-32B, KAT-Coder:
Advancing Code Intelligence through Scalable Agentic RL
Today, we're thrilled to announce two groundbreaking models in our KAT series: KAT-Dev-32B and KAT-Coder — representing accessible excellence and ultimate performance in code intelligence.
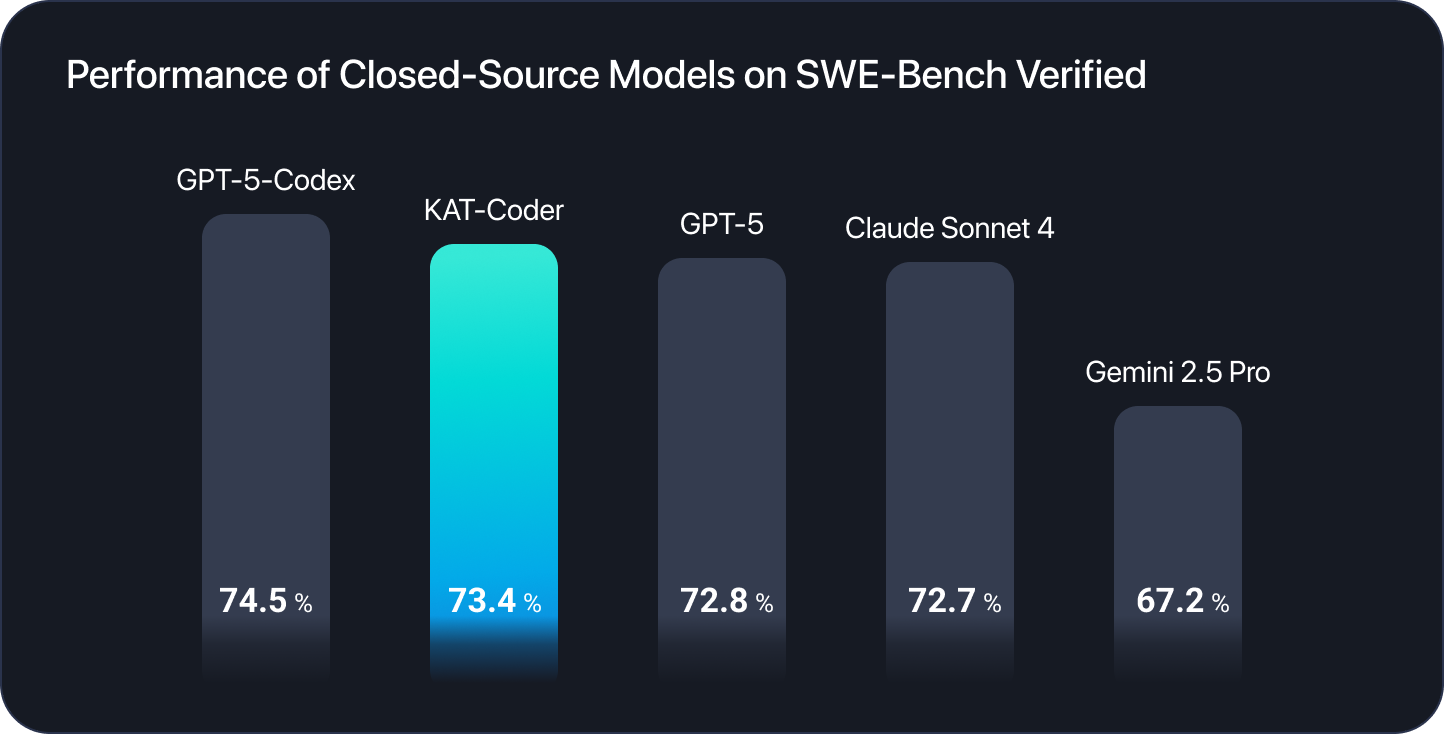
We are excited to introduce KAT-Dev-32B - our new open-source 32B-parameter model for software engineering tasks. On SWE-Bench Verified, KAT-Dev-32B achieves comparable performance with 62.4% resolved and ranks 5th among all open-source models with different scales.

Meanwhile, the most powerful variant: KAT-Coder, achieves 73.4% and marks a superior performance on SWE-Bench Verified.
Key Contributions
Our KAT-Dev-32B and KAT-Coder are optimized via several stages of training, including a mid-training stage, supervised fine-tuning (SFT) & reinforcement fine-tuning (RFT) stage and an large-scale agentic reinforcement learning (RL) stage. In summary, our contributions include:
Mid-Training
We observe that adding extensive training for tool-use capability, multi-turn interaction, and instruction-following at this stage may not yield large performance gains in the current results (e.g., on leaderboards like SWE-bench), but it will have a significant impact on the subsequent SFT and RL stages.
SFT & RFT
We meticulously curated eight task types and eight programming scenarios during the SFT stage to ensure the model's generalization and comprehensive capabilities. Moreover, before RL, we innovatively introduced an RFT stage with "teacher trajectories" annotated by human engineers as guidance during training.
Agentic RL Scaling
Scaling agentic RL hinges on three challenges:
- efficient learning over nonlinear trajectory histories
- leveraging intrinsic model signals
- building scalable high-throughput infrastructure
We address these with prefix caching on log-prob computation, entropy-based trajectory pruning, and SeamlessFlow architecture.
Open Access
Open Source
KAT-Dev-32B is released to the community for further research and development: Hugging Face.

API Key
You can also get accessed to our strongest variant KAT-Coder by simply requesting an API key on StreamLake platform and install Claude Code to start coding, with a detailed technical report coming soon.

KAT-Dev-32B & KAT-Coder
Mid-Training
We fine-tuned a pretrained model with a two-stage process we call "Mid-Train." In the first stage, we enhanced the model's comprehensive capabilities related to "LLM as an agent," including:
-
Tool-use capability: Built interaction data for thousands of tools with real executions in sandbox environments
-
Multi-turn interaction: Constructed dialogues spanning up to hundreds of turns among humans, assistants, and tools
-
Coding knowledge injection: Added high-quality, domain-specific coding knowledge
-
Git commit/PR data: Incorporated large volumes of real pull request data from Git repositories
-
Instruction following: Collected 30+ categories of common user instructions
-
General and reasoning data: Strengthened general-domain capabilities and reasoning
SFT
In the second stage, we collected real delivery trajectories labeled by human engineers and synthesized extensive trajectory data to enhance end-to-end requirement delivery capabilities.
Eight types of user tasks:
- Feature Implementation
- Feature Enhancement
- Bug Fixing
- Refactoring
- Performance Optimization
- Test Case Generation
- Code Understanding
- Configuration & Deployment
Eight major programming scenarios:
- Application Development
- UI/UX Engineering
- Data Science & Engineering
- Machine Learning & AI
- Database Systems
- Infrastructure Development
- Specialized Programming Domains
- Security Engineering
Reinforcement Finetune
At this stage, building on the reinforcement learning (RL) pipeline, we introduce multiple ground truths to guide trajectory exploration, improving rollout efficiency and thereby enhancing the efficiency and stability of the RL phase. By shifting from absolute rewards to measuring discrepancies from ground truth, we further stabilize the RL stage.
Transitioning from directly assigning absolute rewards to evaluating the relative differences between rollout samples and ground truth provides a more stable and accurate reward signal for RL. Meanwhile, we supervise sample correctness in real time during rollouts and promptly terminate generations that clearly deviate from the ground truth, which also yields higher sample efficiency for RL.
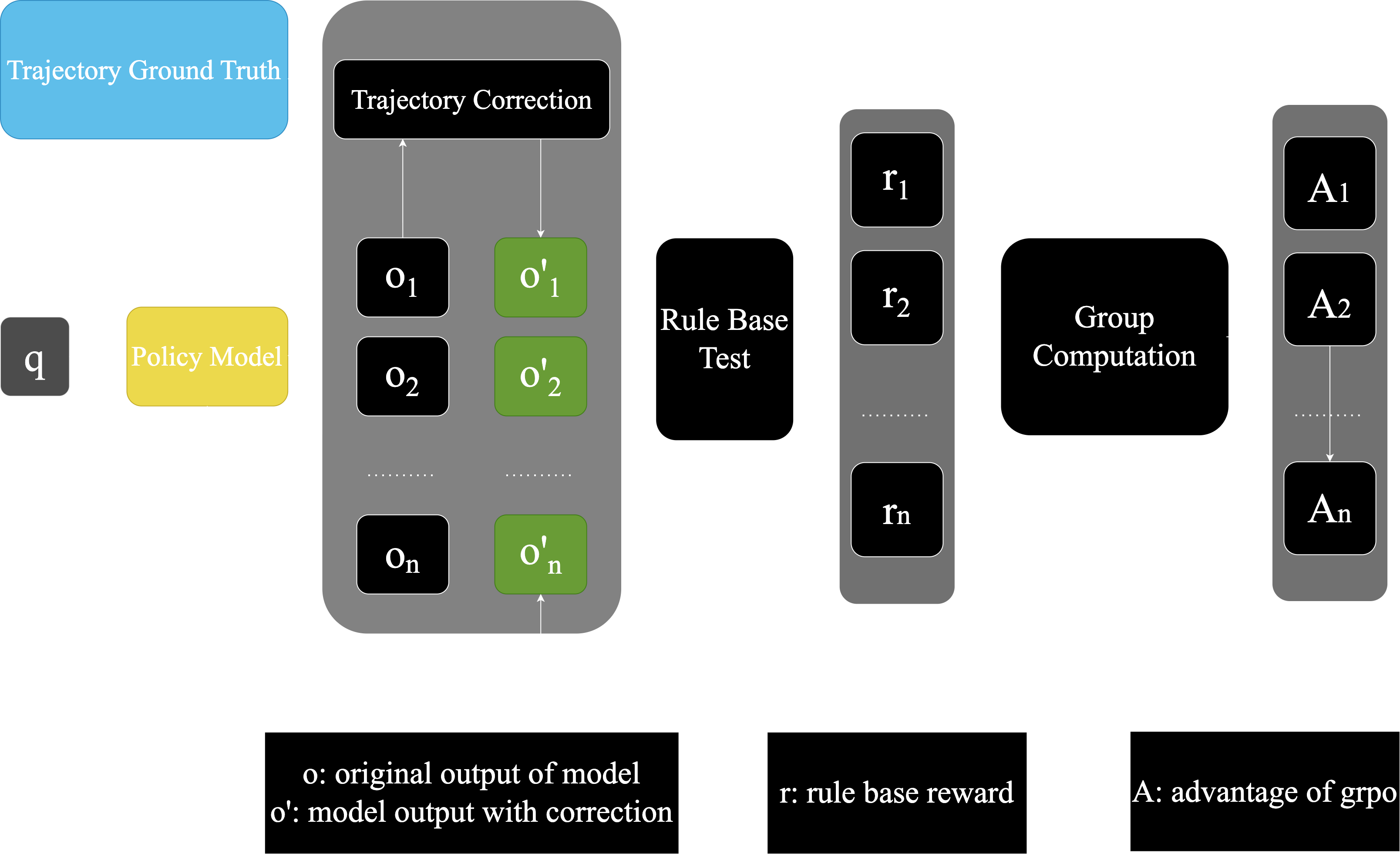
After three training stages, we obtain a cold-start model prepared for RL, and the introduction of Reinforcement Finetuning (RFT) also builds a bridge between SFT and RL:
-
Mid-Training: First, we teach the model a variety of basic skills, including how to use tools and how to understand user intent.
-
SFT: Then, using high-quality trajectory data, the model learns to perform real downstream tasks.
-
RFT: Finally, before the model begins "free exploration," teacher trajectories provide hands-on guidance on how to explore, which also ensures stability in the subsequent RL phase.
Agentic RL Scaling
Entropy Based Tree Pruning
Even with the above mentioned technique, performing training through all tokens in the full tree still remains prohibitively expensive. Thus, we need a mechanism to prioritize nodes that carry the strongest training signals.
To this end, we compress trajectories into a prefix tree where each node represents a shared prefix and each edge corresponds to a segment of tokens. Under a fixed compute budget, the goal is to retain only the most valuable nodes for training. We estimate the informativeness of nodes based on entropy signals aggregated across the tree and their likelihood of being reached, and then prune the tree by expanding nodes in order of importance until the budget is exhausted. Additional heuristics ensure that structurally important regions (e.g., tool or memory events) are preserved and that local context is maintained for stable training. This entropy-based pruning enables us to substantially reduce redundant computation while retaining most of the effective training signal, leading to significant throughout gains and lower overall cost.
RL Infrastructure - SeamlessFlow
To scale RL, it is essential to fully decouple RL training from the diverse internal logic of agents, while also maximizing the utilization of heterogeneous computational architectures. Following the design of SeamlessFlow, we implemented an intermediate layer between agents and RL training dedicated to trajectory-tree management, ensuring strict separation between the two. In addition, we adopted the proposed tag-driven scheduling mechanism to orchestrate task allocation across heterogeneous clusters, thereby minimizing pipeline bubbles and sustaining high-throughput training.
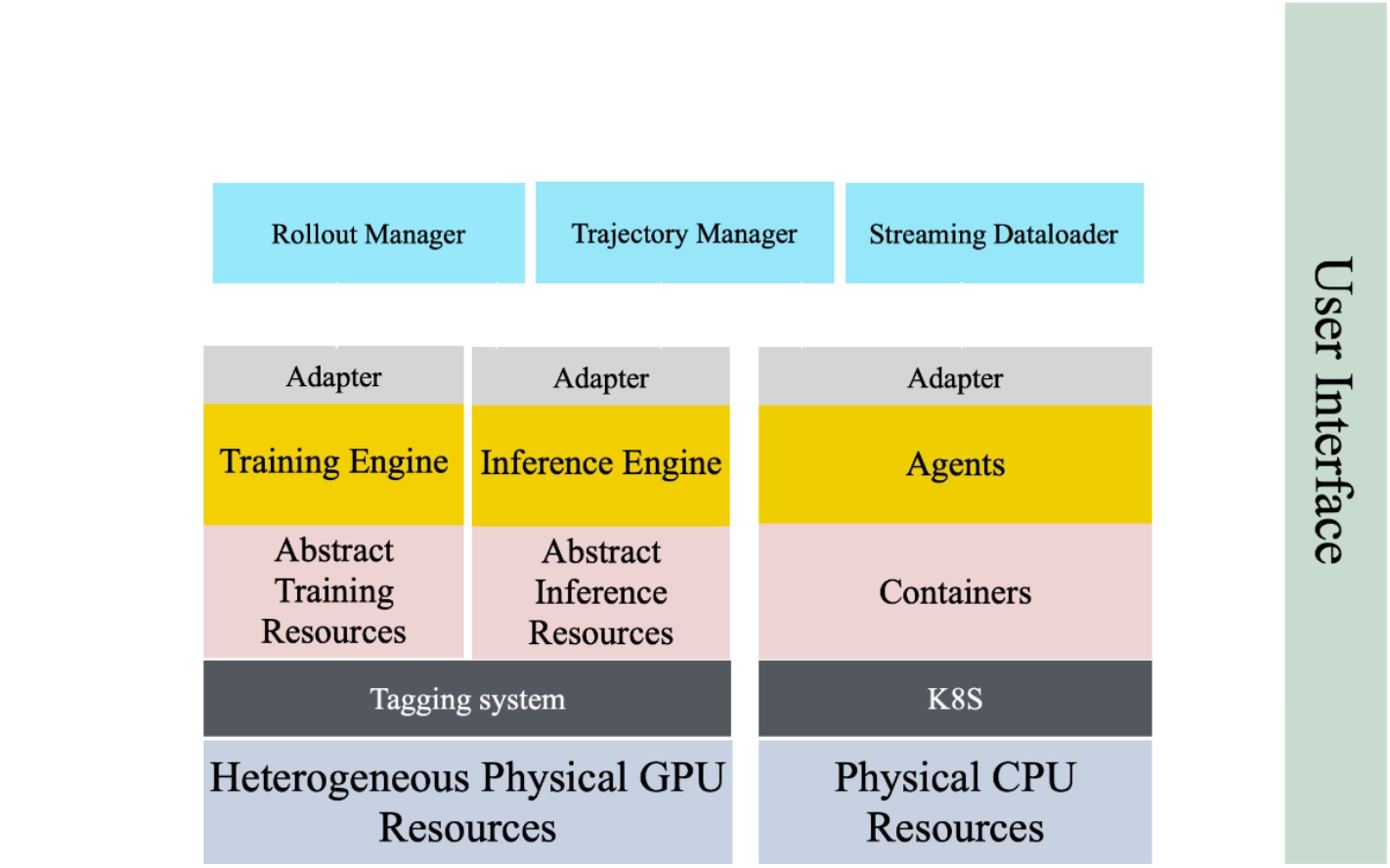
Unified Environment Interface and RL Data Construction
We unify the deployment and evaluation interfaces across different RL execution environments, enabling any newly added environment to be seamlessly integrated at low cost. This unified design lays a solid foundation for scaling RL training across heterogeneous data sources and task types. Specifically, for software development scenarios, we focus on three essential components: problem descriptions paired with corresponding branch code, executable environments, and verifiable test cases. We collect pull requests and the associated issues from open-source repositories and some internal repositories, and filter low-quality data based on the stars, PR activities, and the issue content of these repositories. We then systematically construct executable environment images and generate unit test cases for each collected instance. In addition to software engineering data, we also incorporate other verifiable domains such as math and reasoning tasks, further enriching the diversity of RL signals.
More importantly, beyond open-source data, we further collect and leverage anonymized, enterprise-grade codebases derived from real-world industrial systems for RL training. Unlike training solely on public repositories (like those on GitHub), which often contain simpler projects, these large-scale, complex codebases—spanning multiple programming languages and representing genuine business logic—expose models to significantly more challenging development scenarios, providing highly valuable assets for RL. Training agents to solve such real-world industrial problems not only enhances learning robustness but also grounds the resulting models' programming proficiency in realistic, production-level contexts.
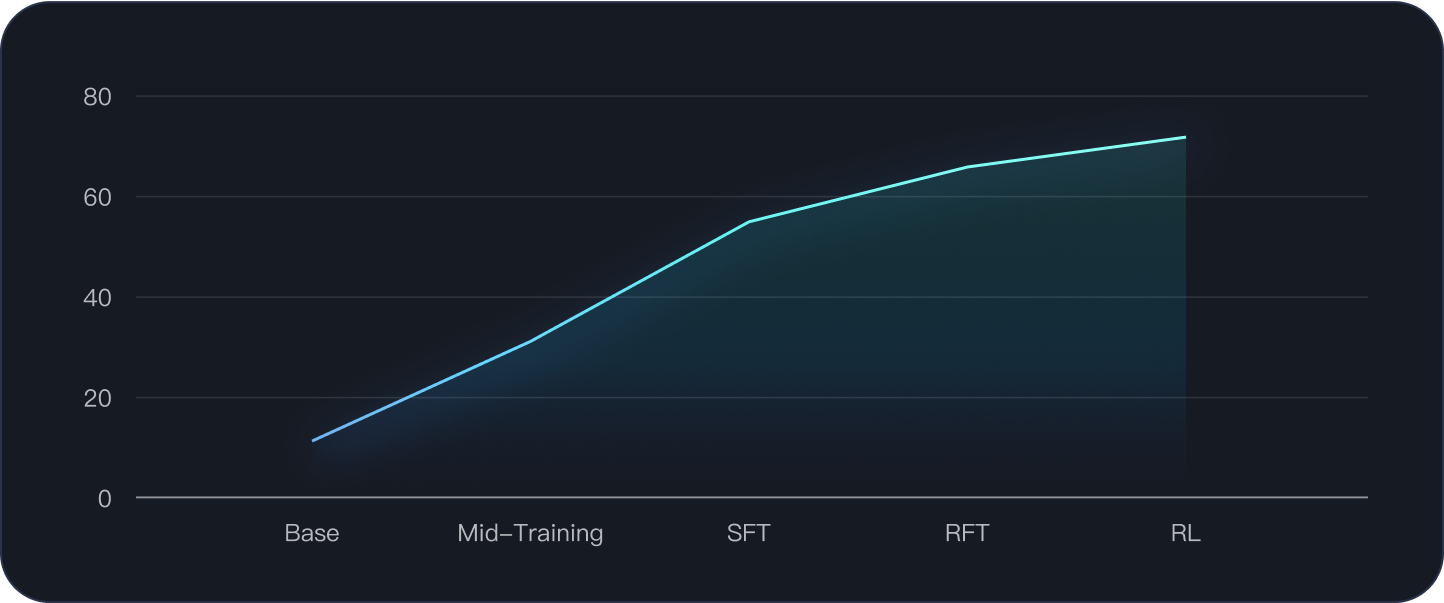
Below is how we observed the model's performance change on SWE-Bench Verified:
Code with KAT-Coder
Claude Code
KAT-Coder is now available for use with Claude Code. Simply request an API key and End Point ID on the StreamLake Wanqing platform and install Claude Code to start coding.
npm install -g @anthropic-ai/claude-codeObtain the API key and create an inference endpoint according to the document.
# replace 'ep-xxx-xxx' with your Wangqing End Point ID
export ANTHROPIC_BASE_URL=https://wanqing.streamlakeapi.com/api/gateway/v1/endpoints/ep-xxx-xxx/claude-code-proxy
# replace 'WQ_API_KEY' with your Wangqing API KEY
export ANTHROPIC_AUTH_TOKEN=WQ_API_KEYThen you should be able to use Claude Code with KAT-Coder!
User Cases


Emergent Behaviors after Agentic RL Scaling
During our agentic RL scaling, we observed significant emergence:
Observed Behaviors
Substantial Reduction in Multi-turn Interactions: The model demonstrates a capability to complete tasks with fewer interaction turns, with an average decrease of 32% in the interaction turns compared to the model trained after SFT stage.
Parallel Tool Calling: After trained with our RL stage, the model exhibits the capability to call for multiple tools simultaneously, departing from the conventional sequential calling paradigm.
Theoretical Analysis
We hypothesize that the emergence primarily arise from the latent optimization objective introduced by the trajectory tree structure:
Formation of Efficiency Preference: Within a trajectory tree, shorter paths (corresponding to fewer interaction turns) are shared across a larger number of trajectories, which creates a latent optimization objective whereby the model learns to propose more efficient solution strategies.
Natural Selection of Parallelization: In the tree structure, parallel tool calling creates additional branching possibilities. These branches are processed independently during training, enabling the model to simultaneously explore various tool calling. Furthermore, our Long-Term Entropy Pruning mechanism preserves tree nodes with more information, and nodes with multi-tool calling typically exhibit higher entropy. This process gradually guides the model towards acquiring a "batch processing" capability.
Future Work
We are committed to pushing the boundaries of what's possible in code intelligence:
Enhanced Tool Integration
Deep integration with popular IDEs, version control systems, and development workflows to create seamless coding experiences.

Multi-Language Expansion
Extending our models' capabilities to cover emerging programming languages and frameworks, ensuring comprehensive language support.
Collaborative Coding
Exploring multi-agent systems where KAT models can work together on complex software projects, enabling unprecedented collaboration.

Multimodal Code Intelligence
Integrating visual understanding capabilities to process architecture diagrams, UI designs, debugging screenshots, and documentation images alongside code, making the development process more intuitive and efficient.

